itp-blog
Week 4
These are the results of my analysis:
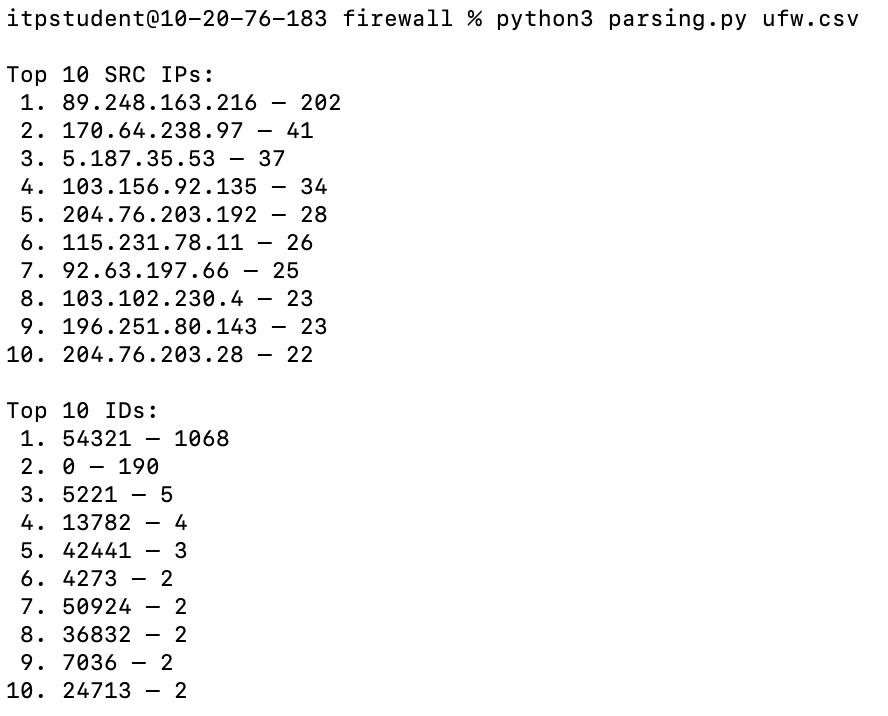
First, I had to locate the ufw.log.
Then, I had to copy the ufw.log from the remote server to my local computer over SSH.
I converted the ufw.log to a .csv.
downloads % sed 's/ /,/g' ufw.log › ufw.csv
ChatGPT conversation below.
This conversation was generated with Duck.ai (https://duck.ai) using OpenAI’s GPT-5 mini Model. AI chats may display inaccurate or offensive information (see https://duckduckgo.com/duckai/privacy-terms for more info).
====================
User prompt 1 of 3 - 9/21/2025, 2:23:38 PM: I have a CSV that has six columns, containing entries like: SRC=167.94.138.109, LEN=60, TOS=0x00,PREC=0x00, TTL=57, ID=8957. This is a UFW log. I want you to help me write code to parse this log.
GPT-5 mini:
Python parser for UFW CSV-style lines
Below is a concise Python function that parses lines like: SRC=167.94.138.109, LEN=60, TOS=0x00, PREC=0x00, TTL=57, ID=8957 and returns dictionaries with typed values (IP as string, integers for numeric fields, hex parsed where appropriate). It also handles extra fields if present.
import csv
import re
from typing import Dict, Any, Iterable, List
KEY_INT = {"LEN", "TTL", "ID"}
KEY_HEX = {"TOS", "PREC"}
KEY_STR = {"SRC", "DST", "PROTO", "MAC"} # extend as needed
_def_hex = re.compile(r"^0x[0-9a-fA-F]+$")
def parse_kv_pair(kv: str) -> (str, Any):
k, _, v = kv.partition("=")
k = k.strip()
v = v.strip()
if not v:
return k, None
if k in KEY_INT:
try:
return k, int(v)
except ValueError:
return k, v
if k in KEY_HEX or _def_hex.match(v):
# parse hex (keep original if parse fails)
try:
return k, int(v, 16)
except Exception:
return k, v
# fallback: IP-like or quoted strings remain strings
if k in KEY_STR or re.match(r"^\d{1,3}(\.\d{1,3}){3}$", v):
return k, v
# try integer fallback
try:
return k, int(v)
except ValueError:
return k, v
def parse_ufw_line(line: str) -> Dict[str, Any]:
"""
Parse a single CSV-style UFW line into a dict.
Example input:
"SRC=167.94.138.109, LEN=60, TOS=0x00,PREC=0x00, TTL=57, ID=8957"
"""
# Normalize separators (some logs may use ", " or ",")
parts = [p.strip() for p in re.split(r",\s*", line.strip()) if p.strip()]
result: Dict[str, Any] = {}
for part in parts:
# Some tokens may be like "PROTO=TCP" or "MAC=aa:bb:cc:.."
k, v = parse_kv_pair(part)
# If key already exists, convert to list
if k in result:
if isinstance(result[k], list):
result[k].append(v)
else:
result[k] = [result[k], v]
else:
result[k] = v
return result
def parse_ufw_csv(lines: Iterable[str]) -> List[Dict[str, Any]]:
"""
Parse an iterable of UFW log lines (CSV-like key=value fields).
Returns a list of dicts.
"""
return [parse_ufw_line(l) for l in lines if l and l.strip()]
# Example usage
if __name__ == "__main__":
sample = "SRC=167.94.138.109, LEN=60, TOS=0x00,PREC=0x00, TTL=57, ID=8957"
print(parse_ufw_line(sample))
# For a file:
# with open("ufw.log") as f:
# records = parse_ufw_csv(f)
# for r in records:
# print(r)
Notes:
- KEY_INT / KEY_HEX / KEY_STR can be extended for other known keys (e.g., DST, SPORT, DPORT, PROTO).
- Hex fields are converted to integers (0x00 → 0). If you prefer to keep hex strings, remove KEY_HEX handling.
- The parser tolerates extra/missing spaces and repeated keys.
User prompt 2 of 3 - 9/21/2025, 2:25:12 PM: I should have been more clear. I want to write Python code that keeps track of which IP addresses in SRC=# and which IDs in ID=# show up the most, keeping a tally of which IDs and IP addresses are most common.
GPT-5 mini:
Top SRC IPs and ID counters — Python script
Below is a concise Python script that reads a UFW log file (lines like “SRC=…, LEN=…, ID=…”), extracts SRC and ID fields, tallies counts, and prints the top N most common SRC IPs and IDs. It handles missing fields and large files efficiently by streaming.
#!/usr/bin/env python3
import re
from collections import Counter
from typing import Iterable, Tuple
KV_RE = re.compile(r"(?P<k>[A-Z]+)=([^,]+)")
def extract_src_id(line: str) -> Tuple[str | None, int | None]:
"""
Return (src_ip, id_int) or (None, None) if not present/parsable.
"""
src = None
idv = None
for m in KV_RE.finditer(line):
k = m.group("k")
v = m.group(0).split("=", 1)[1].strip()
if k == "SRC":
src = v
elif k == "ID":
try:
idv = int(v)
except ValueError:
idv = None
return src, idv
def tally_from_lines(lines: Iterable[str]) -> Tuple[Counter, Counter]:
src_counter = Counter()
id_counter = Counter()
for line in lines:
if not line or not line.strip():
continue
src, idv = extract_src_id(line)
if src:
src_counter[src] += 1
if idv is not None:
id_counter[idv] += 1
return src_counter, id_counter
def print_top(counter: Counter, top_n: int = 20, label: str = "") -> None:
print(f"Top {top_n} {label}:")
for i, (item, cnt) in enumerate(counter.most_common(top_n), 1):
print(f"{i:2d}. {item} — {cnt}")
print()
def main(log_path: str, top_n: int = 20):
with open(log_path, "r", encoding="utf-8", errors="ignore") as f:
src_c, id_c = tally_from_lines(f)
print_top(src_c, top_n, "SRC IPs")
print_top(id_c, top_n, "IDs")
if __name__ == "__main__":
import argparse
p = argparse.ArgumentParser(description="Count top SRC IPs and IDs in UFW log lines.")
p.add_argument("logfile", help="Path to UFW log file (text)")
p.add_argument("-n", "--top", type=int, default=20, help="How many top entries to show")
args = p.parse_args()
main(args.logfile, args.top)
Notes and quick tips:
- Script streams the file (memory efficient).
- It treats ID as integer counts; malformed IDs are skipped.
- If your log lines have different capitalization or extra spaces, the regex still matches uppercase keys; adjust KV_RE to r”(?i)(?P
[a-z]+)=([^,]+)" for case-insensitive keys. - To get results as dicts or JSON, replace print_top usage with counter.most_common() and json.dump.
User prompt 3 of 3 - 9/21/2025, 2:26:19 PM: Where does this Python code read in the CSV? The CSV is called ufw.csv, for your information.
GPT-5 mini: The script I gave reads whichever file path you pass as the positional argument to the program (argument name “logfile”). It does not hard-code ufw.csv.
To read ufw.csv specifically, either:
-
Run the script with the filename: python3 script.py ufw.csv
-
Or change the default in the script by replacing the argparse call or main invocation. Example minimal change — replace the if name block with:
if __name__ == "__main__":
main("ufw.csv", top_n=20)
Either approach makes the script read ufw.csv.